Tantangan dan Potensi AI dalam Generate Pantun Tradisional Indonesia: Komparasi Model GPT-2 dan BLOOM
Pendahuluan
Bicara soal pantun, pasti langsung teringat dengan budaya Indonesia yang kental dengan kearifan lokal. Pantun memang punya tempat istimewa dalam hati masyarakat Indonesia, dikenal dengan irama elegannya dan kemampuan bercerita yang luar biasa. Berasal dari tradisi sastra Melayu, pantun memiliki struktur unik berupa empat baris dengan rima antara baris kedua dan keempat.
Pantun ini punya ciri khas dengan pola rima ABAB, di mana dua baris pertama atau yang disebut “sampiran” seringkali mengandung bahasa kiasan yang menyiapkan latar belakang cerita, sementara dua baris terakhir atau “isi” menghantarkan pesan utama. Maknanya tak hanya sekadar kesan visual, tapi juga berfungsi dalam berbagai aspek kehidupan masyarakat Indonesia, mulai dari upacara tradisional hingga hiburan kontemporer.
Dalam folklore Indonesia, pantun berperan sebagai medium komunikasi yang memupuk hubungan antar komunitas melalui bait-baitnya yang ritmis dan naratif alegorisnya, bergema di berbagai suasana, mulai dari perayaan pernikahan hingga siaran radio dan televisi. Dengan kemampuannya menyampaikan pesan yang penuh dengan kecerdasan dan kebijaksanaan, pantun telah menyatu dalam kehidupan sehari-hari, memperkaya percakapan dan memupuk ikatan budaya.
Meskipun kehadirannya tetap kuat, pantun menghadapi tantangan di zaman modern, dengan penyimpangan dari aturan tradisional yang didorong oleh munculnya bentuk sastra populer dan media digital. Tantangan ini menimbulkan kekhawatiran di kalangan pelestari budaya dan para akademisi, menyoroti perlunya mempertahankan integritas struktural dan tematik dari pantun klasik di tengah perubahan lanskap budaya. Menemukan keseimbangan ini tetap menjadi tantangan kontemporer, terutama dalam memastikan bahwa adaptasi modern dari pantun tetap setia pada esensi tradisionalnya sambil tetap menarik dan relevan dalam konteks kontemporer.
Sementara itu, di dunia Natural Language Processing (NLP), terjadi kemajuan signifikan, terutama dalam domain generasi teks. Generasi pantun pada sub-bidang NLP, fokus pada penciptaan pantun secara otomatis dan telah menarik minat besar karena kompleksitas intrinsiknya. Tugas ini membutuhkan model untuk menyeimbangkan kreativitas linguistik, kohesi struktural, dan kedalaman semantik, menjadikannya area studi yang menarik.
Terobosan terbaru dalam AI, terutama dengan pengembangan model berbasis transformer seperti GPT-2 dan BLOOM, telah menunjukkan potensi dalam menghasilkan pantun yang koheren dan estetis. GPT-2, yang diperkenalkan oleh OpenAI, terkenal dengan kemampuannya menghasilkan teks yang menyerupai manusia tanpa memerlukan pelatihan yang spesifik. Sementara BLOOM, model berbasis transformer lainnya, telah muncul sebagai pesaing GPT-2 dengan tujuan meningkatkan tugas generasi teks dengan menggabungkan informasi kontekstual tambahan dan merinci proses generatif.
Tulisan ini bertujuan untuk mengeksplorasi efektivitas GPT-2 dan BLOOM dalam menghasilkan pantun tradisional Indonesia, membandingkan kinerja keduanya untuk memahami model mana yang lebih baik mempertahankan esensi budaya dan struktural dari pantun. Selain itu, studi ini bertujuan untuk memperkenalkan dan mengevaluasi metodologi untuk menilai akurasi dan kreativitas pantun yang dihasilkan oleh AI, berkontribusi pada wacana yang lebih luas tentang peran AI dalam penciptaan sastra dan pelestarian budaya. Kode lengkapnya dapat dilihat di sini.
Dengan menganalisis secara sistematis kemampuan model NLP canggih ini dalam konteks generasi pantun, tulisan ini berusaha menjawab pertanyaan-pertanyaan berikut: Seberapa baik model berbasis GPT dan BLOOM menyesuaikan diri dengan struktur tradisional pantun? Apakah model ini dapat menghasilkan pantun yang relevan secara budaya dan estetis? Apa batasan dan area potensial untuk perbaikan dalam generasi pantun berbasis AI?
Metode
Dalam tulisan ini, kita bakal menjalankan metode yang komprehensif dan sistematis buat capai tujuan kita dalam generasi pantun. Nah, kita punya bingkai kerja utama yang terdiri dari enam tahapan yang berbeda: pre-processing, pembagian dataset, encoding, fine-tuned dan pelatihan model, pantun generation, dan evaluasi model.
A. Pengumpulan dan Pra-Pemrosesan Dataset
Dataset pantun yang dipakai dalam penelitian ini dikumpulkan secara manual dari berbagai sumber internet yang open dari Kaggle (donikusuma-pantun-indonesia), (ilhamfp31/pantun-indonesia), dari blog dan web (gramedia), serta dari buku. Dataset ini terdiri dari total 29.169 kata, dengan 6.155 kata unik dan 345 kata dasar/stopwords unik. Selain itu, dataset ini terdiri dari 58.361 suku kata. Dataset utuh setelah dipreprocessing dapat diunduh di link berikut ini. Sementara kode preprocessing ada di sini.

Tahapan Preprocessing meliputi:
- Penghapusan anotasi dalam tanda kurung dan teks yang tidak relevan dengan korpus pantun, seperti nama penulis dan detail publikasi, dihapus.
- Penghapusan dan penggantian karakter khusus seperti elipsis (…) dan garis bawah (_) dihapus dari dataset untuk memastikan keseragaman dan keterbacaan. Beberapa karakter seperti titik koma (;), tanda apostrof (‘), dan emotikon (misalnya, 😀, 😛) diganti atau dihapus untuk menstandarisasi teks.
- Format kalimat titik-titik (..), koma (,,,), tanda tanya (???), dan karakter lain yang berulang diganti dengan satu kemunculan untuk menjaga struktur kalimat. Spasi berlebih dan karakter newline dipangkas dan disstandarisasi untuk meningkatkan konsistensi teks. Setiap baris pantun dipisahkan dengan “\n”.
- Penyaringan data segmen teks tertentu, termasuk baris tambahan dan anotasi, disaring atau dihapus untuk memastikan integritas dan keseragaman data.
Setelah langkah-langkah pra-pemrosesan ini, entri duplikat dihapus dari dataset, memastikan setiap pantun tetap unik. Dataset yang dihasilkan siap untuk analisis lebih lanjut dan pelatihan model, dengan fokus pada generasi dan evaluasi pantun. Selain itu, eksperimen dilakukan dengan rasio pembagian data latih-uji 90:10 untuk menilai kemampuan generalisasi model pada data yang nggak terlihat.
B. Model untuk Generasi Pantun
Setiap model, GPT, GPT-2, dan BLOOM, menawarkan keuntungan unik untuk generasi pantun otomatis. GPT memberikan fondasi yang kuat dengan keunikan dan kohesi, meskipun arsitekturnya lebih sederhana. GPT-2 melambangkan lompatan ke depan dengan arsitektur yang lebih besar dan pemahaman linguistik yang lebih halus, memungkinkan output pantun yang lebih canggih. Sementara itu, BLOOM membedakan dirinya melalui penggunaan inovatif dari filter BLOOM, memastikan pola rima dan irama yang efisien.
1.GPT
GPT, atau Generative Pre-trained Transformer, muncul sebagai inovasi terobosan dalam pemrosesan bahasa alami saat diperkenalkan pada tahun 2018. Dikembangkan oleh OpenAI, GPT melambangkan pergeseran paradigma dalam bidang generasi bahasa AI-driven. Berbeda dengan pendahulunya, GPT memanfaatkan kekuatan transformatif dari arsitektur transformer, yang memungkinkannya untuk memproses dan menghasilkan teks dengan kelancaran dan kohesi yang lebih baik. Kode pelatihan model GPT ada di sini.
2. GPT-2
GPT-2, terobosan revolusioner dalam pemrosesan bahasa alami sejak tahun 2019, menjadi lambang inovasi dalam generasi pantun. Berakar dalam arsitektur transformer yang transformatif, GPT-2 melambangkan pergeseran paradigma dalam kreativitas komputasional. Menggambar inspirasi dari pendahulunya GPT, GPT-2 mencerminkan inti dari pre-training generatif, memanfaatkan korpora teks yang luas untuk membudayakan pemahaman mendalam tentang struktur bahasa dan semantik. Kode pelatihan model GPT-2 ada di sini.
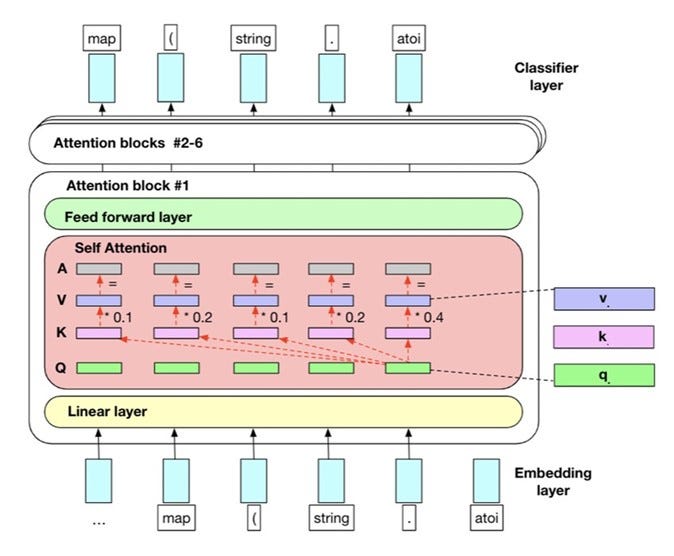
3. BLOOM
BLOOM, singkatan dari “Bidirectional Language Model with Transformers for Machine Comprehension,” mewakili kemajuan yang signifikan dalam pemrosesan bahasa alami, khususnya dalam domain pemahaman mesin. Diperkenalkan sebagai pendekatan baru oleh para peneliti, BLOOM membangun di atas fondasi yang dibuat oleh model bahasa berbasis transformer seperti BERT (Bidirectional Encoder Representations from Transformers). Kode pelatihan model BLOOM ada di sini.
C. Metrik Evaluasi
Metrik evaluasi memainkan peran penting dalam menilai efektivitas dan kualitas teks yang dihasilkan dalam tugas generasi bahasa alami (NLG). Dalam penjelasan komprehensif ini, kita akan membahas setiap metrik evaluasi yang digunakan: perplexity, lexical richness, akurasi struktur, dan kebenaran rima.
1.Perplexity
Perplexity adalah metrik yang umum digunakan dalam tugas NLG, terutama dalam pemodelan bahasa. Ini mengukur seberapa baik model bahasa memprediksi sampel teks. Dalam konteks generasi pantun, perplexity mengukur tingkat ketidakpastian atau “kejutan” yang terkait dengan prediksi model. Nilai perplexity yang lebih rendah menunjukkan bahwa model bahasa memberikan probabilitas yang lebih tinggi pada urutan kata sebenarnya dalam teks.
2. Lexical Richness
Lexical richness merujuk pada keragaman dan variasi kosakata yang digunakan dalam teks yang dihasilkan. Ini mengukur kemampuan model untuk menghasilkan teks dengan berbagai kata, menghindari pengulangan dan kosakata yang terbatas. Salah satu metrik umum yang digunakan untuk mengevaluasi lexical richness adalah rasio tipe-token (TTR), yang menghitung rasio kata unik (tipe) terhadap jumlah total kata (token) dalam teks.
3. Akurasi Struktur
Akurasi struktur menilai ketaatan teks yang dihasilkan terhadap struktur atau format yang telah ditentukan. Dalam konteks generasi pantun, ini mengevaluasi apakah pantun yang dihasilkan mengikuti bentuk pantun yang ditentukan, seperti jumlah baris, susunan bait, dan skema rima. Misalnya, dalam evaluasi generasi pantun, akurasi struktur memeriksa apakah setiap pantun terdiri dari empat baris dengan pembagian yang tepat menjadi dua baris “Sampiran” dan dua baris “Isi.”
4. Kebenaran Rima
Kebenaran rima mengevaluasi akurasi pola rima dalam pantun yang dihasilkan. Ini mengukur seberapa baik model menangkap dan mereproduksi rima sesuai dengan skema rima yang ditentukan, seperti AABB atau ABAB. Dalam tugas generasi pantun, kebenaran rima penting untuk menghasilkan pantun dengan akhiran yang estetis dan konsisten secara ritmis.
Hasil dan Pembahasan
Dalam bagian hasil dan diskusi, diamati variasi signifikan dalam model terbaik yang memiliki metrik kinerja terbaik di antara berbagai model yang dievaluasi, seperti yang digambarkan dalam tabel dan grafik di bawah ini:
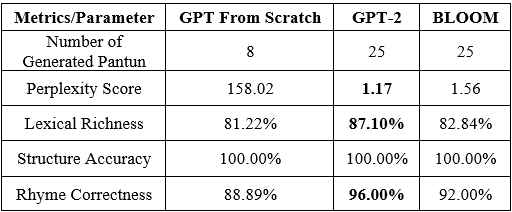
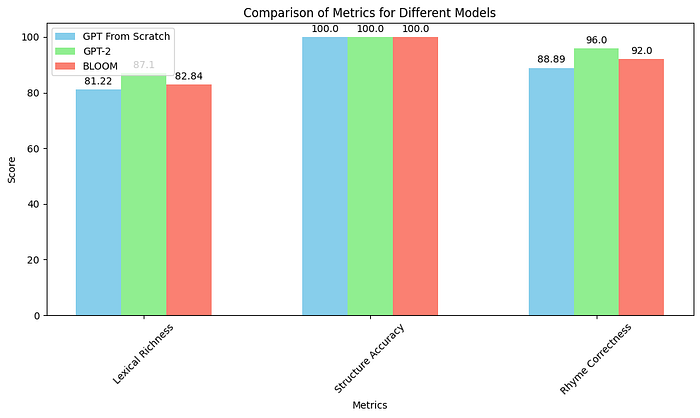

Model GPT From Scratch menunjukkan skor perplexity tertinggi sebesar 158.02, menandakan kemampuan model yang relatif lebih rendah dalam memprediksi token berikutnya dalam urutan dibandingkan dengan model lainnya. Sebaliknya, baik model GPT-2 maupun BLOOM menunjukkan skor perplexity yang jauh lebih rendah, masing-masing 1.17 dan 1.56, menunjukkan tingkat koherensi dan prediktabilitas yang lebih tinggi dalam teks yang dihasilkan. Perbedaan skor perplexity ini dapat dikaitkan dengan perbedaan dalam ukuran data pelatihan, arsitektur model, dan teknik optimisasi yang digunakan selama pelatihan.
Model GPT-2 mencapai skor lexical richness tertinggi sebesar 87.10%, diikuti dengan cukup dekat oleh model GPT From Scratch sebesar 82.88%, sementara model BLOOM menunjukkan skor lexical richness sebesar 82.84%. Lexical richness mencerminkan keragaman kosakata yang digunakan dalam teks yang dihasilkan. Lexical richness yang lebih tinggi yang diamati dalam model GPT-2 dapat dikaitkan dengan kosakata pra-pelatihan yang lebih besar dan penyetelan halus pada korpora teks yang luas.
Semua model, GPT, GPT-2, dan BLOOM, mencapai skor akurasi struktur yang sempurna sebesar 100%, menunjukkan bahwa semua output yang dihasilkan sesuai dengan struktur pantun yang benar.
Model GPT-2 menunjukkan skor kebenaran rima tertinggi sebesar 96%, diikuti oleh model BLOOM sebesar 92%, sementara model GPT From Scratch mencapai skor kebenaran rima sebesar 88.89%. Kebenaran rima mengukur akurasi pola rima dalam pantun yang dihasilkan. Kinerja superior model GPT-2 dalam kebenaran rima dapat dikaitkan dengan kemampuannya dalam menangkap pola linguistik dan hubungan semantik yang rumit selama pelatihan.
Disparitas dalam metrik kinerja di antara model yang dievaluasi menyoroti pentingnya arsitektur model, kualitas data pelatihan, dan teknik optimisasi dalam menentukan efektivitas pantun yang dihasilkan oleh AI. Sementara model GPT-2 menunjukkan kinerja superior dalam berbagai metrik, model GPT From Scratch menunjukkan hasil yang kompetitif meskipun data pelatihan dan sumber daya komputasi yang terbatas. Penelitian dan eksperimen lebih lanjut diperlukan untuk menjelajahi potensi arsitektur dan metodologi pelatihan yang baru dalam meningkatkan kualitas dan kreativitas pantun yang dihasilkan oleh AI.



Integrasi dengan Chatbot Gradio
Kode untuk membuat UI chatbot gradio ada di sini.
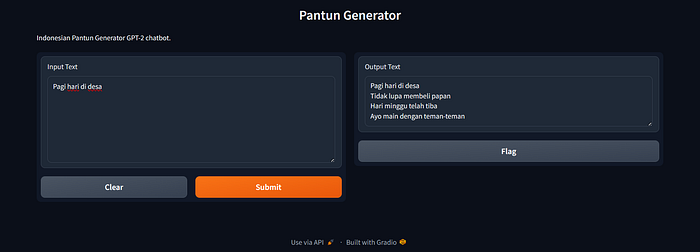
Untuk integrasi dengan chatbot, pada Gambar di atas, sistem terintegrasi berhasil menghasilkan komposisi pantun sebagai tanggapan atas input pengguna, menunjukkan efektivitas model GPT-2 dalam menangkap esensi pantun Indonesia. Model GPT-2 dilatih menggunakan korpus besar pantun untuk mempelajari pola dan struktur dasar dari bentuk pantun tersebut. Fine-tuning melibatkan penyesuaian parameter model untuk mengoptimalkan kinerjanya secara khusus untuk generasi pantun. Antarmuka Gradio dirancang untuk terintegrasi secara mulus dengan model GPT-2, memungkinkan pengguna berinteraksi dengan sistem melalui antarmuka pengguna yang sederhana dan intuitif. Antarmuka chatbot meningkatkan keterlibatan pengguna, memberikan platform bagi pengguna untuk mengeksplorasi kreativitas mereka dan menyatakan diri melalui pantun.
Kesimpulan
Berdasarkan analisis komparatif generasi pantun menggunakan model GPT From Scratch, GPT-2, dan BLOOM, beberapa temuan kunci muncul. Model berbasis GPT dan BLOOM menunjukkan tingkat kualitas yang baik dalam menyesuaikan diri dengan struktur tradisional pantun. Keduanya mampu menghasilkan pantun yang sesuai dengan format dan struktur yang telah ditetapkan dengan akurasi 100%. Namun, dalam hal penggunaan bahasa dan tema, GPT-2 menunjukkan hasil yang lebih baik dengan akurasi 96% dalam kebenaran rima. Meskipun demikian, baik GPT-2 maupun BLOOM mampu menghasilkan pantun yang relevan secara budaya dan estetis, dengan kemampuan untuk memperoleh nilai lexikalitas yang tinggi, serta konsistensi dalam struktur dan kebenaran rima.
Secara keseluruhan, hasil tadi menegaskan efektivitas GPT-2 dalam menghasilkan pantun berkualitas tinggi, menyoroti potensinya untuk tugas generasi bahasa alami. Batasan utama yang terlihat adalah pada penggunaan model “From Scratch” GPT, yang menunjukkan nilai perplexity yang tinggi dan kemampuan lexikalitas yang lebih rendah dibandingkan dengan model lainnya. Selain itu, meskipun model-model ini mampu menghasilkan pantun yang sesuai dengan struktur tradisional, masih ada potensi untuk meningkatkan kemampuan mereka dalam memahami konteks budaya yang lebih mendalam, sehingga menghasilkan pantun yang lebih mendalam secara kultural dan estetis. Perbaikan dalam generasi pantun berbasis AI dapat melibatkan pengembangan model yang lebih canggih dalam memahami nuansa bahasa dan tema, serta pembaruan dalam dataset latihan untuk memperkaya keragaman budaya yang direpresentasikan dalam pantun yang dihasilkan.
Referensi
[1] R. Kartika and M. Mulyadi, “Noun Phrases in Aceh Language Pantun Collections,” East Asian J. Multidiscip. Res., vol. 3, no. 4, pp. 1615–1630, 2024, doi: 10.55927/eajmr.v3i4.7544.
[2] E. Sugianto, Mengenal sastra lama: jenis, definisi, ciri, sejarah, dan contoh: pantun, karmina, syair, gurindam, seloka, talibun, mantra, peribahasa, pepatah …. Penerbit Andi, 2015.
[3] R. Setyadiharja, Khazanah Negeri Pantun. Deepublish, 2020.
[4] Y. Bagastian, H. Usman, and T. T. Adi, “Pantun as Local Cultural Literation Media for Elementary School Students in Indonesia,” Indones. J. Educ. Res. Rev., vol. 6, no. 2, pp. 433–445, 2023, doi: 10.23887/ijerr.v6i2.57687.
[5] R. Isnendes, “Material artifacts of Sundanese looms with hypogram on the figure of Nyai Pohaci in carita pantun Lutung Kasarung,” Indones. J. Appl. Linguist., vol. 12, no. 3, pp. 752–764, 2023, doi: 10.17509/ijal.v12i3.47942.
[6] H. N. Irmanda, R. Astriratma, N. Chamidah, and M. M. Santoni, “Pembuat Sampiran Pantun Otomatis berbasis Pattern-matching,” J. Sisfokom (Sistem Inf. dan Komputer), vol. 10, no. 3, pp. 306–311, 2021, doi: 10.32736/sisfokom.v10i3.1221.
[7] Z. Hu, C. Liu, Y. Feng, A. T. Luu, and B. Hooi, “PoetryDiffusion: Towards Joint Semantic and Metrical Manipulation in Poetry Generation,” Proc. AAAI Conf. Artif. Intell., vol. 38, no. 16, pp. 18279–18288, 2024, doi: 10.1609/aaai.v38i16.29787.
[8] P. M. Kiasari, “Towards Measuring Coherence in Poem Generation,” 2022.
[9] T. Nguyen et al., “SP-GPT2: Semantics Improvement in Vietnamese Poetry Generation,” Proc. — 20th IEEE Int. Conf. Mach. Learn. Appl. ICMLA 2021, pp. 1576–1581, 2021, doi: 10.1109/ICMLA52953.2021.00252.
[10] M. E. G. Beheitt and M. B. H. Hmida, “Automatic Arabic Poem Generation with GPT-2,” Int. Conf. Agents Artif. Intell., vol. 2, no. Icaart, pp. 366–374, 2022, doi: 10.5220/0010847100003116.
[11] M. Hämäläinen, K. Alnajjar, and T. Poibeau, “Modern French Poetry Generation with RoBERTa and GPT-2,” Proc. 13th Int. Conf. Comput. Creat. ICCC 2022, no. Veale 2016, pp. 12–16, 2022.
[12] F. Aguilar-Canto, M. Cardoso-Moreno, D. Jiménez, and H. Calvo, “GPT-2 versus GPT-3 and Bloom: LLMs for LLMs Generative Text Detection,” CEUR Workshop Proc., vol. 3496, 2023.
[13] J. Wei, Q. Zhou, and Y. Cai, “Poet-based Poetry Generation: Controlling Personal Style with Recurrent Neural Networks,” in 2018 International Conference on Computing, Networking and Communications (ICNC), 2018, pp. 156–160. doi: 10.1109/ICCNC.2018.8390270.
[14] L. Wang, “Comparative analysis of automatic poetry generation systems based on different recurrent neural networks,” in 3D Imaging — Multidimensional Signal Processing and Deep Learning: 3D Images, Graphics and Information Technologies, Volume 1, Springer, 2022, pp. 169–177.
[15] P. D. Iswara, Pantun Bertema untuk Bahan Ajar di Sekolah Dasar, Sekolah Menengah Pertama, Sekolah Menengah Atas dan Perguruan Tinggi. 2012.
[16] G. Yenduri et al., “GPT (Generative Pre-Trained Transformer) — A Comprehensive Review on Enabling Technologies, Potential Applications, Emerging Challenges, and Future Directions,” IEEE Access, vol. 12, pp. 54608–54649, 2024, doi: 10.1109/ACCESS.2024.3389497.
[17] A. Dai, “GPT-2 for Emily Dickinson poetry generation,” Cs230.Stanford.Edu, [Online]. Available: http://cs230.stanford.edu/projects_fall_2021/reports/103051256.pdf
[18] T. Le Scao et al., “BLOOM: A 176B-Parameter Open-Access Multilingual Language Model,” Nov. 2023. [Online]. Available: https://inria.hal.science/hal-03850124
[19] A. Vaswani et al., “Attention is all you need,” Adv. Neural Inf. Process. Syst., vol. 30, 2017.
[20] S. Chen, D. Beeferman, and R. Rosenfeld, “Evaluation metrics for language models,” Proc. DARPA Broadcast News Transcr. Underst. Work., pp. 275– 280, 1998, [Online]. Available: http://repository.cmu.edu/cgi/viewcontent.cgi?article=2330&context=compsci
[21] D. Colla, M. Delsanto, M. Agosto, B. Vitiello, and D. P. Radicioni, “Semantic coherence markers: The contribution of perplexity metrics,” Artif. Intell. Med., vol. 134, no. July, 2022, doi: 10.1016/j.artmed.2022.102393.
[22] E. A. Siallagan and I. Alfina, “Poetry Generation for Indonesian Pantun Using SeqGAN and GPT-2,” J. Ilmu Komput. dan Inf., vol. 16, no. 1, pp. 59–67, 2023, doi: 10.21609/jiki.v16i1.1113.
[23] “A Conversational Chatbot that Rhymes,” no. May, 2022.
